Chapter 5: Fully Sharded Data Parallel (FSDP)¶
PyTorch Fully Sharded Data Parallel (FSDP) speeds up model training by parallelizing training data and sharding model parameters, optimizer states, and gradients across multiple GPUs.
If your model does not fit on a single GPU, you can use FSDP and request more GPUs to reduce the memory footprint on each GPU. The model parameters are split between the GPUs and each training process receives a different subset of training data. Model updates from each device are broadcast across devices, resulting in the same model on all devices.
For a complete overview with examples, see the PyTorch FSDP Tutorial.
Highly recommended read: FSDP explained visually
If you want a really intuitive, visual explanation of FSDP, check out FSDP Explained Blog post from Clika. It explains how parameters transition between sharded and unsharded states, and how all-gather and reduce-scatter work together in practice. It's one of the best breakdowns of FSDP I've seen.

How FSDP Works¶
FSDP shards model parameters across GPUs so that each GPU stores only 1/N of the model, where N is the number of GPUs.
During training, parameters temporarily transition between two states:
1. Sharded state , where parameters are split across GPUs
2. Unsharded state – full parameters are reconstructed for computation
Here is the high-level lifecycle of a parameter shard during training with 4 GPUs:
-
At the beginning — each GPU holds 1/4 of params:
GPU 0: [shard 0]
GPU 1: [shard 1]
GPU 2: [shard 2]
GPU 3: [shard 3] -
Before forward —
all-gatheris used to reconstruct full params:
GPU 0: [shard 0 | shard 1 | shard 2 | shard 3] (temporary)
GPU 1: [shard 0 | shard 1 | shard 2 | shard 3] (temporary)
GPU 2: [shard 0 | shard 1 | shard 2 | shard 3] (temporary)
GPU 3: [shard 0 | shard 1 | shard 2 | shard 3] (temporary)Info
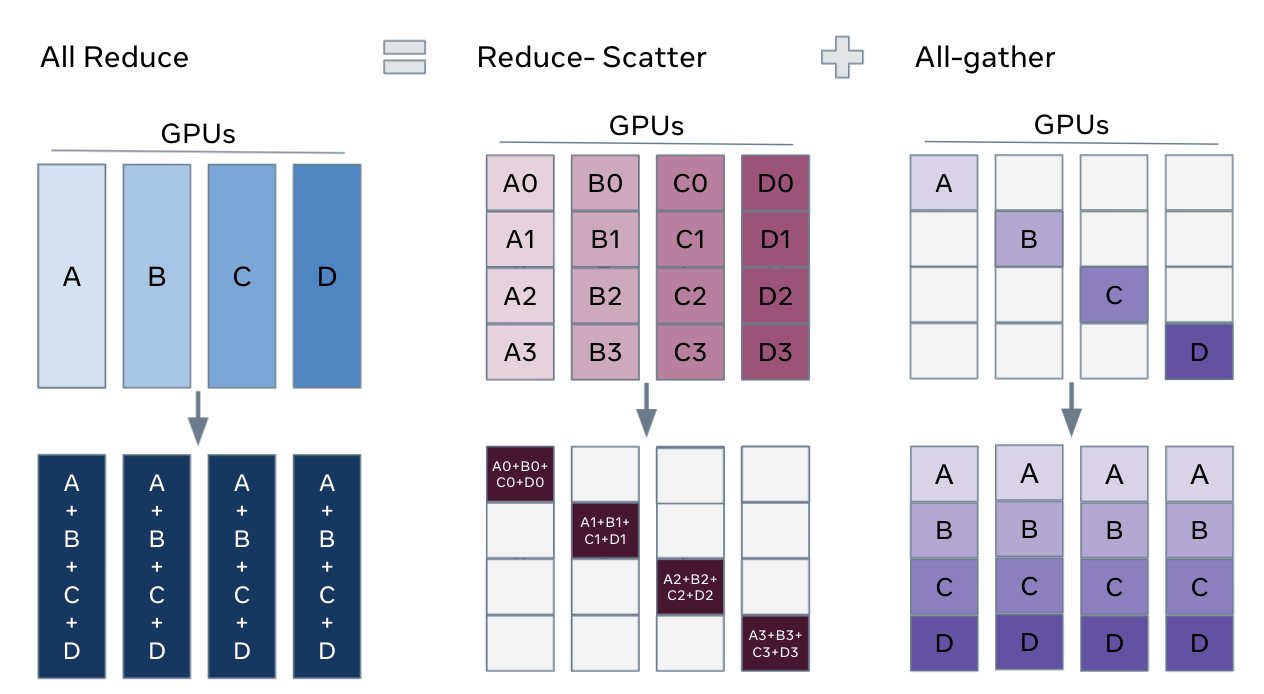
all-gatheris covered in detail in the PyTorch Collective Communication chapter — it gathers shards from all GPUs to reconstruct the full parameter tensor on each GPU. -
Now, we can compute forward pass, using full params.
-
After forward pass, we can discard non-local shards to save memory and return to sharded state, i.e. :
GPU 0: [shard 0] (back to 1/4)
GPU 1: [shard 1] (back to 1/4)
GPU 2: [shard 2] (back to 1/4)
GPU 3: [shard 3] (back to 1/4) -
Before backward pass, we need to
all-gatheragain. -
After backward pass, we need to
reduce-scattergradients across GPUs so that each GPU only holds the gradients for its shard: GPU 0: [grad shard 0] (already reduced + sharded)
GPU 1: [grad shard 1] (already reduced + sharded)
GPU 2: [grad shard 2] (already reduced + sharded)
GPU 3: [grad shard 3] (already reduced + sharded) -
Optimizer step — each GPU updates only its shard
In pseudo-code:
FSDP forward pass:
for layer_i in layers:
all-gather full weights for layer_i
forward pass for layer_i
discard full weights for layer_i
FSDP backward pass:
for layer_i in layers:
all-gather full weights for layer_i
backward pass for layer_i
discard full weights for layer_i
reduce-scatter gradients for layer_i
From DDP to FSDP¶
Migrating from DDP to FSDP usually requires minimal code changes. Replace DDP(model) with FSDP(model) and add a wrapping policy:
# DDP version:
from torch.nn.parallel import DistributedDataParallel as DDP
model = DDP(model, device_ids=[local_rank])
# FSDP version:
from torch.distributed.fsdp import FullyShardedDataParallel as FSDP
from torch.distributed.fsdp.wrap import size_based_auto_wrap_policy
import functools
auto_wrap_policy = functools.partial(
size_based_auto_wrap_policy, min_num_params=100_000
)
model = FSDP(
model,
auto_wrap_policy=auto_wrap_policy,
sharding_strategy=ShardingStrategy.FULL_SHARD,
device_id=local_rank,
)
The training loop stays the same — zero_grad → forward → backward → step.
Sharding Strategies¶
FSDP offers three strategies with different memory/speed tradeoffs:
| Strategy | What's Sharded | Memory | Communication | When to Use |
|---|---|---|---|---|
FULL_SHARD |
Params + gradients + optimizer | Lowest | Highest (all-gather + reduce-scatter) | Model barely fits across all GPUs |
SHARD_GRAD_OP |
Gradients + optimizer | Medium | Medium (reduce-scatter only) | Model fits but optimizer doesn't |
NO_SHARD |
Nothing (like DDP) | Highest | Lowest (all-reduce only) | Debugging / comparison |
from torch.distributed.fsdp import ShardingStrategy
# Maximum memory savings
model = FSDP(model, sharding_strategy=ShardingStrategy.FULL_SHARD, ...)
# Less communication, more memory
model = FSDP(model, sharding_strategy=ShardingStrategy.SHARD_GRAD_OP, ...)
Mixed Precision¶
FSDP works with mixed precision to further reduce memory. On A100 GPUs, BFloat16 is the preferred format:
from torch.distributed.fsdp import MixedPrecision
mixed_precision = MixedPrecision(
param_dtype=torch.bfloat16, # compute in BF16
reduce_dtype=torch.bfloat16, # communicate in BF16
buffer_dtype=torch.bfloat16, # buffers in BF16
)
model = FSDP(
model,
mixed_precision=mixed_precision,
...
)
This halves memory for parameters during computation and halves the data sent during all-gather and reduce-scatter.
Wrapping Policies¶
FSDP doesn't shard the model as a single giant unit. If it did, the all-gather step would reconstruct the entire model at once, immediately causing an Out-Of-Memory error! Instead, it wraps sub-modules individually so memory is only spiked layer-by-layer.
Size-based (simple)¶
Wrap any module with more than N parameters:
Module-type based (precise)¶
Wrap specific architectural blocks. This is standard practice for Transformer-based weather models (like Pangu-Weather or Aurora). You want to wrap at the Transformer Block level.
from torch.distributed.fsdp.wrap import ModuleWrapPolicy
# Wrap each transformer block individually
auto_wrap_policy = ModuleWrapPolicy({TransformerBlock})
Wrapping at the right granularity matters: too coarse and you lose sharding benefit; too fine and communication overhead dominates.
The Checkpointing Caveat¶
Because each GPU only holds a fraction of the weights, you cannot simply call torch.save(model.state_dict(), "model.pt"). In that case, you will only save 1/N of the model!
So, you must tell FSDP to gather the model before saving:
from torch.distributed.fsdp import FullStateDictConfig
from torch.distributed.fsdp import StateDictType
# Configure FSDP to gather weights to CPU (to avoid GPU OOM)
save_policy = FullStateDictConfig(offload_to_cpu=True, rank0_only=True)
with FSDP.state_dict_type(model, StateDictType.FULL_STATE_DICT, save_policy):
cpu_state_dict = model.state_dict()
if local_rank == 0:
torch.save(cpu_state_dict, "full_weather_model.pt")
Running the Examples¶
# Single node, 4 GPUs
torchrun --standalone --nproc_per_node=4 \
scripts/02_fully_sharded_fsdp/resnet_fsdp_training.py
# With mixed precision
torchrun --standalone --nproc_per_node=4 \
scripts/02_fully_sharded_fsdp/resnet_fsdp_training.py --use-amp
# Via PBS job script
qsub scripts/02_fully_sharded_fsdp/run_fsdp.sh
See also:
- scripts/02_fully_sharded_fsdp/resnet_fsdp_training.py — FSDP training with ResNet-18 on CIFAR-10
- scripts/02_fully_sharded_fsdp/README.md — deep dive on FSDP
FSDP vs FSDP2 (and why it matters for what’s next)
Under development
You may see references to FSDP2 in newer PyTorch materials.
FSDP2 is the next-generation version of FSDP built on top of PyTorch’s
distributed tensor (DTensor) APIs, enabling more flexible and composable parallelism.
Why this matters:
As models scale, we often combine multiple parallelism strategies:
- FSDP → shard model states (memory)
- Tensor Parallel → shard computation (within layers)
- Pipeline Parallel → shard model depth
FSDP2 is designed to make these combinations cleaner and more natural.
In the next chapter, we introduce Tensor Parallelism, which splits computation within layers—something FSDP alone cannot do.
🔗 Good resource:
FSDP1 vs FSDP2 (Hugging Face Accelerate)
What's Next?¶
FSDP shards entire parameters across all GPUs layer-by-layer. But what if a single layer's weight matrix is so massively wide that even gathering it temporarily causes an OOM? Tensor Parallelism solves this by splitting the actual matrix multiplication across GPUs.